Système immuable
Publié le 22-09-2022 à 11:19:42 ‐ Lecture 6 min
Nous commencons une série de billet au sujet des systèmes immuable.
Avant de commencer des billets un peu plus technique, nous commençons par donner notre vision de ce qu'est un système immuable. En effet, il y beaucoup de manière d'envisager et d'implémenter des systèmes immuables avec toujours des avantages et des inconvénients. Comme souvent, il n'y a pas de solution unique et idéale.
Immuable ?
Définition
Si nous prennons la définition de Wiktionnaire immuable veut dire "qui n’est pas sujet à changer, en parlant des choses éternelles".
L'idée c'est qu'une fois déployé, le système doit rester inchangé. Les évolutions et les corrections seront apportées à chaque fois par une nouvelle version.
Cela implique :
- reproductibilité des constructions
- gestion du cycle de vie
- séparation des données suivant leur durée de vie
Il y a déjà beaucoup de littérature sur le sujet. Vous trouverez facilement une définition plus complète que celle donnée ici.
Image Système immuable
Nous ne parlons pas d'"image immuable" (comme c'est souvent le cas) mais de "système immuable". Dans notre esprit, il faut que le système soit immuable par lui même.
Souvent, les solutions proposées reposent sur une infrastructure qui permet cette immuabilité (docker, AWS, ...). Le système en lui même est mutable mais la plateforme dispose de solutions de "hard reset" qui annule tous les changements pour revenir à la situation de base.
Reposer sur la plateforme ne me semble pas la solution la plus pertinente. Et ceux pour plusieurs raisons :
- il n'est pas de séparation claire entre les données mutables et les données immuables
- il faut connaitre précisément la configuration de l'infrastructure pour savoir ce qui l'est ou ne l'est pas
- il faut avoir accès à la plateforme pour revenir à la situation initiale, si on "bricole" sur le système il faut demander à la plateforme explicitement de revenir à la situation initiale
- suivant la plateforme il est possible d'avoir des comportements différents
- il faut installer le système sur une plateforme spécifique, mais comment installer cette plateforme de façon immuable ? C'est l'histoire du serpent qui se mort la queue cette histoire ...
- ...
Séparation suivant le type de données
Séparer les données suivant leur type est un élément central de notre conception du système immuable.
L'idée étant de séparer les données sur des disques différents suivant leur "mutabilité" et leur cycle de vie. Bien évidement cela sera géré différemment avec les conteneurs (avec des points de montage différent) et les machines physiques (avec potentiellement qu'un disque) mais le principe sera le même.
Les disques
Voici les trois types de disques nécessaire :
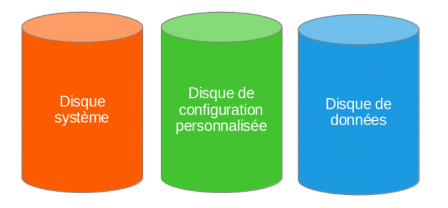
Le disque système
Ce disque comprend toutes les données provenant de la distribution :
- les applications et les bibliothèques
- les fichiers de configuration fournit par la distribution
- l'approvisionnement de base réalisé par la distribution
Le principe c'est que ce disque doit être utilisable, sans modification, par plusieurs instances. Ce disque est donc complètement générique.
Le disque de configuration personnalisée
Ce disque comprend donc toute la personnalisation du système. Que cela soit :
- les fichiers de configuration des applications
- les fichiers divers spécifiques : les certificats SSL, ...
- les "units" systemd
- tout ce qu'il faut pour personnaliser l'approvisionnement les services
Le disque de données
Ce disque est initialement vide. Il sera remplit durant toute la vie du système.
Cela peut être :
- les fichiers temporaires utiles à l'exécution d'un service
- les fichiers produits par un utilisateur
- une base de données
- ...
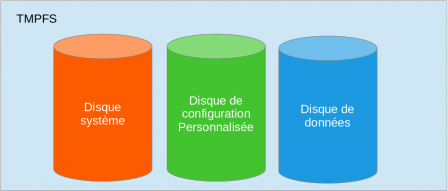
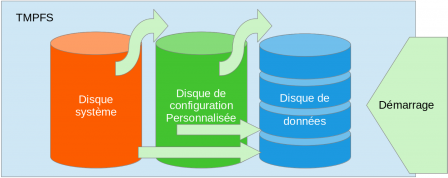
La machine
La machine finale sera donc composée de nos trois disques.
Il nous manque encore quelque chose pour avoir une machine fonctionnelle ... la racine.
La racine ne sera pas sur un disque particulier. Elle sera en RAM (TMPFS).
Voici donc la composition de notre machine :
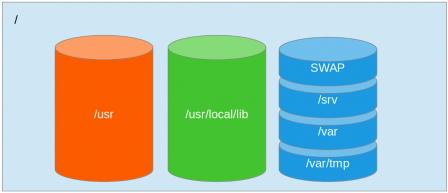
Le partitionnement
Les trois disques sont partitionnés comme suit :
-
/ est en mémoire (TMPFS)
-
/usr est le seul répertoire récupérer dans le disque sytème (cela signifie qu'il faudra préparer la distribution en conséquence)
-
/usr/local/lib est le disque de configuration personnalisée
-
le disque de donnée sera partitionné en quatre (ou moins) :
- SWAP
- /srv
- /var
- /var/tmp
En voici une illustration :
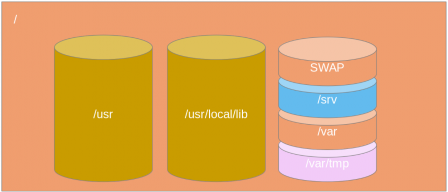
La "mutabilité" des données
Maintenant que nous avons la liste des partitions, voyons la "mutabilité" des données sur cette partition :
- les données immuables (/usr et /usr/local/lib), ce sont des données accessibles qu'en lecture, les données ne sont donc pas mise à jour mais les disques sont reconstruits et remis à disposition
- les données mutables (/srv), ce sont des données accessibles en lecture/écriture, elles ne sont jamais supprimées sans intervention manuelle de l'utilisateur
- les données mutables temporaires (/, /var et la SWAP), ce sont des données accessibles en lecture/écriture, elles sont supprimées à chaque démarrage de la machine
- les données mutables temporaires limités (/var/tmp), ce sont des données accessibles en lecture/écriture, elles sont supprimées à chaque démarrage de la machine et de façon régulière suivant différents critères (espace disque occupé, temporalité, ...)
Nous avons donc :
La sauvegarde des données
Seule les données mutables (/srv) sont sauvegardés. Les autres données sont soit reproductible (les données immuables) soit temporaires.
Il peut être préférable d'extraire les données avant sauvegarde pour facilité la restauration (notamment pour faire une restauration partielles d'une base de données) ou pour ne pas sauvegarder des données corrompus (ce qui arrive si on sauvegarde les fichiers d'une base de données en cours d'utilisation).
L'approvisionnement
Pour approvisionner le disque de configuration personnalisée et du disque des données mutables, le premier réflexe serait de penser à un logiciel de gestion de configuration comme Ansible, Salt-stack, Rudder, ...
Même si l'idée est séduisante, nous y voyons plusieurs problèmes :
- la partition des fichiers de configuration personnalisés est immuable, comment mettre à jour ?
- la partition / (donc /etc) est en mémoire, il faut procéder à l'approvisionnement à chaque démarrage, il faut donc que le logiciel de gestion de configuration se charge au début du démarrage de la machine
- le logiciel de gestion de configuration doit avoir accès à tous les réseaux pour pouvoir provisionner toutes les machines
- ...
Pour éviter ces problèmes, comme pour l'infrastructure, c'est le système lui-même qui devra gérer l'approvisionnement des configurations personnalisées.
Les données de configuration personnalisée seront mis à disposition (pourquoi pas les créer à l'avance grâce à un logiciel de gestion de configuration). Les partitions mutables seront approvisionnées également par le système au démarrage de celui-ci.
Maintenant que les principes sont établies, une série de billets préciseront comment mettre en place ce système immuable.